





Abstract
Personalised medicine aims to tailor medical decisions to the individual patient. A possible approach is to stratify patients according to the risk of adverse outcomes such as exacerbations in chronic obstructive pulmonary disease (COPD). Risk-stratified approaches are particularly attractive for drugs like inhaled corticosteroids or phosphodiesterase-4 inhibitors that reduce exacerbations but are associated with harms. However, it is currently not clear which models are best to predict exacerbations in patients with COPD. Therefore, our aim was to identify and critically appraise studies on models that predict exacerbations in COPD patients. Out of 1382 studies, 25 studies with 27 prediction models were included. The prediction models showed great heterogeneity in terms of number and type of predictors, time horizon, statistical methods and measures of prediction model performance. Only two out of 25 studies validated the developed model, and only one out of 27 models provided estimates of individual exacerbation risk, only three out of 27 prediction models used high-quality statistical approaches for model development and evaluation. Overall, none of the existing models fulfilled the requirements for risk-stratified treatment to personalise COPD care. A more harmonised approach to develop and validate high- quality prediction models is needed to move personalised COPD medicine forward.
Abstract
None of the 27 prediction models for COPD exacerbations appears to be ready to support personalised COPD treatment http://ow.ly/Lq2b302IWRx
Introduction
Personalised medicine aims to tailor medical decisions to the individual patient [1, 2]. The interest in personalised respiratory medicine has risen recently but it has not been introduced much into practice yet [3, 4]. For patients with chronic obstructive pulmonary disease (COPD) [5], a possible approach for personalising medical treatments is to stratify patients according to the risk of exacerbations, in order to prescribe treatments such as inhaled corticosteroids or phosphodiesterase-4 inhibitors only if their benefits in terms of reduced risk of exacerbations [6] are expected to outweigh the harms [7–9]. For example, a recent benefit–harm assessment of the phosphodiesterase-4 inhibitor roflumilast suggested that the risk for severe exacerbations requiring hospital admissions needs to be at least 20% over 1 year so that the expected benefits (in terms of reducing severe exacerbations) overcome the gastrointestinal, psychiatric and neurological side effects of roflumilast [7].
Exacerbations are an ideal target for risk-stratified treatment since it is one of the most important outcomes for COPD patients and avoiding them is likely to lead to a higher health-related quality of life, longer life and less healthcare cost. However, a prerequisite for risk-stratified treatment is that the risk of exacerbations can be accurately predicted by a prediction model [10–12] that has been thoroughly developed and validated [13–16]. A number of models predicting exacerbations in COPD patients have been published reporting on combinations of information from patient history, clinical characteristics and test results including biomarkers to predict exacerbations. It is still not clear yet, though, which prediction model predicts exacerbations most accurately and is applicable in daily practice. For this reason, along with the lack of other systematic reviews, the aim of this systematic review was to identify and critically appraise studies presenting models predicting exacerbations in COPD patients that may support risk-stratified and personalised treatment.
Materials and methods
The authors followed the Center for Reviews and Dissemination guidance for the methodology [17] and the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) statement for the reporting [18, 19].
Protocol
We wrote a detailed study protocol in advance (supplementary material). We carefully followed the protocol and recorded any deviations from it.
Search methods
We identified eligible papers through a search of the databases Medline (from 1949), Embase (from 1974) and Scopus (from 1996). The search was performed by an information specialist of the University of Zurich (Zurich, Switzerland). Additional studies were identified through the Pubmed-related articles function and reference list of included studies, author contacts, narrative reviews or the “grey” literature (reports, dissertation, conference abstracts or papers).
Participants
To be eligible for inclusion, patients were required to have a COPD diagnosis according to Global Initiative for Chronic Obstructive Lung Disease (GOLD) criteria (i.e. the ratio between forced expiratory volume in 1 s (FEV1) and forced volume capacity (FVC) had to be <0.7 after bronchodilation).
Outcome definition
The outcome of interest was exacerbation. Exacerbations could be event based (e.g. course of antibiotics and/or oral corticosteroids or admission to hospital) or symptom based (patient-reported change in symptoms with or without use of diary charts).
General selection criteria
Publication status, year of publication and language were not subject to exclusion criteria.
Study design
We included studies with a longitudinal design (prospective or retrospective cohorts) or control arms of randomised control trials (that can be regarded as cohort studies). Length of follow-up was not subject to exclusion criteria.
Selection criteria for prediction models
For inclusion, the analysis section of the paper had to refer to a prediction model [10] or multivariable association [20, 21] of a set of predictors with the outcome exacerbation. By also including multivariable models without explicit reference to prediction models, we broadened the eligibility of models substantially in order to learn as much from the literature as possible. But in order to foresee the use of such multivariable models, which often focused on a single predictor of interest (e.g. a biomarker), while adjusting for other predictors (e.g. previous exacerbations or FEV1 % predicted), a requirement for inclusion was that the model also included four commonly used and easily available predictors (i.e. previous exacerbations, smoking, age, and FEV1 % pred) beside the predictor of interest. Indeed, analyses not accounting for these four common predictors may over-estimate the predictive value of a particular single predictor (such as a biomarker) and there is general consensus that the use of more sophisticated predictors is justified only if they provide additional value when added to commonly available predictors. A further requirement for the inclusion in the systematic review was the presence of at least one performance of the prediction model (e.g. area under the curve (AUC) for discrimination). If information needed to decide on inclusion was not available from the papers we contacted the authors up to two times to obtain them. The studies could also be included if exacerbation was not the only outcome of the study.
Procedure
Two review authors (B. Guerra and C. Bianchi) independently assessed titles and abstracts of all references retrieved. Two review authors (B. Guerra and V. Gaveikaite) independently reviewed full-text versions of potentially relevant studies, and selected the studies. Disagreement was resolved by discussion between the two review authors. If consensus was not reached, a third review author was consulted (M.A. Puhan).
Data extraction and management
Two review authors (B. Guerra and V. Gaveikaite) independently extracted the following data from included studies: demographic characteristics of the study population, disease severity, clinical settings, definition of the outcome, duration of the follow-up, details of the statistical method as well as of the predictors of the final model. All missing information was searched for in the references indicated in the papers (if available), or asked for by email to the authors. Some missing information was retrieved from pharmaceutical companies involved in the studies (if needed, by formal requests).
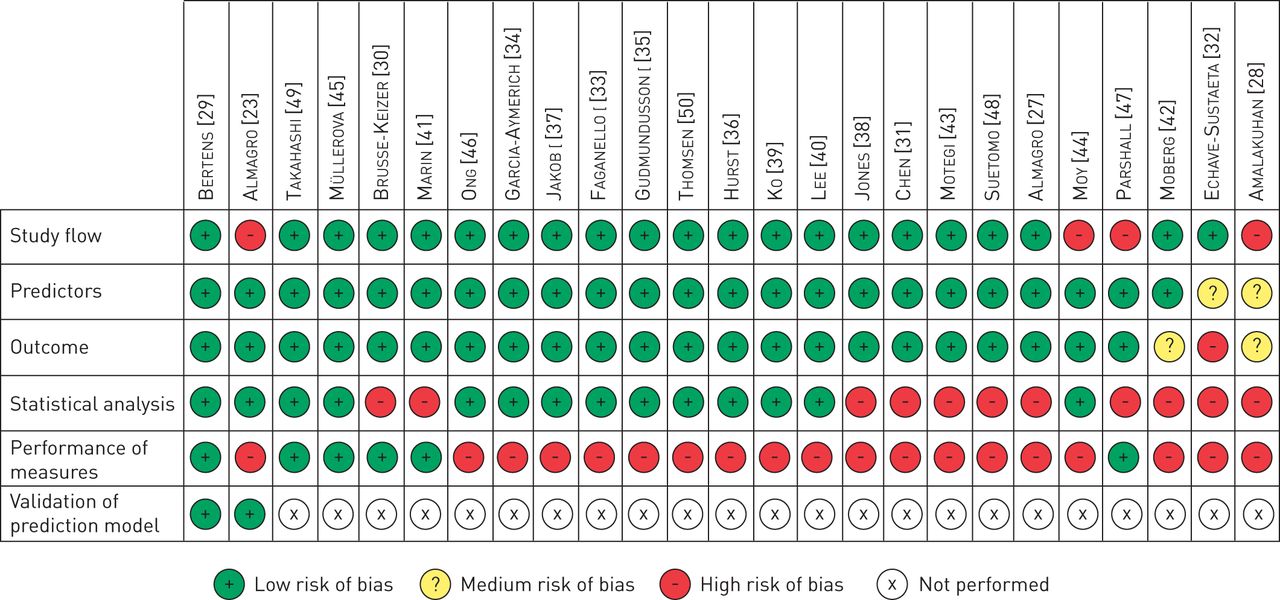
Quality assessment concerned six categories of potential bias (participant selection as shown in the study flow, measurement of predictors, measurement of outcome (i.e. exacerbation), statistical analysis for model development, performance measures and validation, based on guidance from Cochrane [22], an early version of the prediction study risk of bias assessment tool (PROBAST) guidelines (www.systematic-reviews.com/probast) and the needs of this particular systematic review. The criteria for rating studies at low, high or unclear risk of bias as well as a description for each bias category of each included study are shown in the supplementary material.
Some studies reported on small variations of the same prediction model. Since these models performed in general very similarly, we considered one prediction model per study for the main analysis (supplementary material). We only considered more than one prediction model per study if they were substantially different, as in Almagro et al. [23], where the predictive performance of the CODEX (comorbidity, obstruction, dyspnoea and severe exacerbations), ADO (age, dyspnoea and airflow obstruction) and BODEX (body mass index, airflow obstruction, dyspnoea and severe exacerbations) indices were assessed (thus, we will speak in this systematic review of 25 studies and 27 prediction models).
In order to evaluate the readiness of the prediction models for practice we defined a priori three criteria for the clinical applicability of the models. 1) Availability predictors. We deemed the set predictors in each prediction model to be easily (E) available if most of them were based on questions or information from medical charts, to be moderately (M) available if some (at least two) were based on tests routinely done in non-specialised and specialised settings and to be difficult (D) to be available if at least one of the predictor was based on a test usually performed in specialised settings only (details concerning the assessment are explained later in the text and in the supplementary material). 2) External validation. In order to be confidently used in practice, prediction models require validations in populations other than the populations in which it was developed [13, 14, 24]. We had high confidence in the performance if the model had been validated (with a small decrease of performance between derivation and validation cohort) in an external cohort of COPD patients and, accordingly, low confidence if an external validation was lacking. 3) Practical applicability. To be useful for risk-stratified treatment in practice we deemed models to be useful if they provided a simple point system like the BODE (body mass index, airflow obstruction, dyspnoea and exercise capacity) or ADO indices (e.g. [25, 26]) with corresponding risks of exacerbations (e.g. 4 points=25% probability of exacerbation for a specified time horizon), an online calculator or other means to easily derive the risk of exacerbations for an individual patient. We deemed prediction models not ready for risk-stratified treatment yet if only the statistical methods (e.g. regression coefficients) were reported.
Statistical analysis
Given the heterogeneity of the studies we deemed meta-analyses not a sensible approach and reported the findings using descriptive summary statistics.
Results
Selection of studies
Figure 1 shows the study selection process and the main reasons for exclusion at the different stages. From the database searches, we included 20 from a total of 1345 studies. From additional searches we included another five studies and thus a total of 25 papers [23, 27–50] reporting on 27 prediction models (supplementary material for details concerning each stage of the selection process).

Prediction models or multivariable association of a set of predictors with the outcome exacerbation.
Study characteristics
The included studies were conducted in countries around the world (table 1). They are ordered according to categories of exacerbation incidence. Acknowledging the lack of standard in literature for the individual cut-off value (or more cut-off values) for the frequent exacerbator phenotype, and given the commonly used cut-off of 2 exacerbations per person-year [36, 53] we categorised each cohort as low (<1 exacerbation per person-year), moderate (1–2 exacerbations per person-year) or high (≥2 exacerbations per person-year) incidence of exacerbations. Three cohorts with high incidence of exacerbations, four cohorts with moderate incidence of exacerbations and 19 cohorts with low incidence of exacerbations were included (for one of the 27 cohorts, the related data were not retrieved). Sample sizes ranged from 109 to 8020. The definition and measurement of exacerbations was symptom-based in seven (out of 27 cohorts: 25 derivation cohorts plus two validation cohorts), event-based in 17 and unclear definition in three cases. Exacerbations were not adjudicated by a committee in any study. The prediction models were mainly based on prospective cohort studies (control arm of a randomised controlled trial for one model [30]), while two prediction models were based on retrospective cohort studies [28, 46]). Follow-up periods ranged from 14 days to up to 9 years (the most common follow-up was up to 1 year). 21 out of the 25 included studies had the explicit aim to find a combination of predictors strongly associated with exacerbations, while four studies [35, 37, 49, 50] focused on a particular predictor but adjusted for age, FEV1 % predicted, smoking and previous exacerbation (making them eligible for the inclusion in this review).
Study characteristics
Predictors included in the prediction models
More than 50 different predictors were used across the included prediction models (supplementary material). Airways obstruction (FEV1 % predicted or FEV1 or GOLD stage) was the most common predictor (12 times out of 27 models). The next most common predictors were previous exacerbations (nine times), age (nine times), smoking (eight times) and health-related quality of life (eight times). More than half of predictors were included only once.
Quality assessment
21 out of 25 studies reported with low risk of bias on the study flow and the selection of participants (figure 2), 23 out of 25 studies were deemed at low risk of bias for how they measured the predictors and 22 out of 25 studies were deemed at low risk of bias for how they measured exacerbations (given our broad definition of exacerbation). 14 studies were at low risk of bias for how the prediction models were developed statistically and how the statistical analysis was performed (the remaining 11 were at high risk). Six studies were at low risk of bias in terms of the performance measures used (while 19 studies were at high risk). 19 studies out of 25 were of good quality concerning the clinical data (i.e. the three bias categories selection, definition and measurement of predictors and outcomes and in terms of how patients were selected). Three out of 25 models were of good quality from a statistical point of view (i.e. the two categories statistical method and performance evaluation). Finally, two studies [28, 30] performed an internal validation [54] and two studies [23, 29] an external validation (other studies had a validation cohort, but they made a prediction for other outcomes or they did not provide any performance measure for the outcome exacerbation).

{kind=link}
{kind=link}
Framework for bias assessment of the studies evaluating prediction models and multivariable associations of a set of predictors with the outcome exacerbation.
Statistical methods
Table 2 shows a description of the 27 prediction models ordered by underlying statistical method (the details of the two validation cohorts are shown as well, for a total of 29 rows); some papers included different analyses, in one case [40] different statistical methods were shown; in order to avoid confusion for the reader, we have included in table 2 only one statistical method per study, apart from those already discussed [23] (where we included the three indices as three independent prediction models). The most common statistical method was logistic regression (11 out of 25 different statistical methods analysed) followed by Cox regression (10), and correlation analysis between an index (or a multivariable regression equation) with the outcome (three). Finally, Poisson regression model, negative binomial regression model and random forest model were each used once.
Description of prediction models ordered by underlying statistical method
Most of the prediction models (18 out of 27) were directly presenting a model with a predefined index or regression equation with predefined predictors. The remaining nine prediction models used some selection procedure of the variables (i.e. univariable selection process relying on p-values, stepwise selection process relying on p-values, combinations of both or selection process driven by the AUC).
For five prediction models (out of 27), performance related to both discrimination (e.g. AUC) and calibration (e.g. Hosmer–Lemeshow test) were reported (in [29] this is true for both derivation and validation cohort). A measure of discrimination (always AUC) was the most common performance provided (21 times out of 27 prediction models). Measures of overall performance (like R2 or log-likelihood) and of calibration (Hosmer–Lemeshow p-value or Chi-squared) were less common (provided, respectively for 12, three, six and five models). The performance measure provided for the two validation cohorts are the same than the ones for their respective derivation cohorts.
Clinical applicability of the models
The use of prediction models in practice needs to balance the clinical availability of predictors, i.e. the effort to obtain the information, the easiness with which doctors can obtain a risk for the individual patients and the predictive performance of the models. Ideally, predictors would be easily available, the model easy to obtain individual probabilities from, and the model would predict the risk of exacerbations accurately as shown by an external validation.
Table 3 shows the assessment of the readiness of the prediction models for clinical practice. The availability of predictors was based on the assessment of the availability of single predictors and how many of them were in different categories of availability (as shown in the online material, ‘1’ refers to a simple test or simple questions or medical charts, ‘2’ refers to routine tests, ‘3’ refers to specialised tests). 12 out of 27 models were deemed to have an easily available set of predictors across non-specialised and specialised healthcare settings, four out of 27 to have an moderately easy available set of predictors and 11 out of 27 to have a set of predictors whose data is difficult to obtain across healthcare settings. Only two models [23, 29] can be confidently used in other populations because an external validation was performed to assess the transportability of the prediction model [24]. Also, only one study [27] provided a way to easily obtain an estimate of the risk of an exacerbation for an individual patient and thus a basis for risk-stratified treatment. Overall, none of the existing models fulfilled all criteria for being ready for clinical application and use for risk-stratified treatment to personalise COPD care.
Readiness of prediction models for clinical practice
Discussion
Our systematic review identified 25 studies reporting on 27 statistical prediction models for exacerbation in patients with COPD. The prediction models differ greatly in terms of how they were developed and which predictors and measures for their predictive performance were used. Most studies were of good quality concerning the clinical settings and tests (i.e. selection, definition and measurement of predictors and outcomes and in terms of how patients were selected). However, most of the prediction models were at high risk of bias because unsound statistical methods to develop prediction models, and a lack of validation. The overall assessment of readiness of the 27 prediction models for use in practice showed that none were ready for clinical application.
Strengths and limitations
The strengths of this systematic review were the adherence to rigorous systematic review methodology and reporting guidelines, apart from a thorough search strategy and a great effort for retrieving the needed information from the authors. A limitation could be considered the broad inclusion criteria concerning the definition of exacerbation, potentially introducing heterogeneity among models. Furthermore, the adopted broad definition of prediction model could have allowed the inclusion of studies not meant to concern prediction, but only evaluating the association of an index (or a multivariable regression equation) with the outcome. Nevertheless, we deemed our broader approach suitable in order not to miss prediction models that may be useful for clinical practice. Finally, the big heterogeneity of statistical methods used in literature makes probably not valuable to overall compare all the models even if they are providing the same performance measure (e.g. AUC), since they are often too different in terms of definition of exacerbations, time horizon, statistical method and outcome of the prediction model.
Future research
In order to come up with high-quality prediction models for exacerbations in COPD patients, a standard methodology for developing the models should be adopted [55]. For instance, in certain medical fields, some indices were validated and are currently used in clinical setting for risk-stratified prevention and treatment. The cardiovascular field, for example, has a long tradition that started with the Framingham Risk Score predicting the risk of cardiovascular disease [56] and led to clinical guidelines that heavily rely on risk-stratified prevention of cardiovascular disease [57, 58]. In COPD, high-quality prediction models, for example the BODE and ADO indices, have been developed and externally validated for the outcome of mortality [25, 26, 59]. There is also a research need to better understand how prediction models could be made as attractive as possible to use in practice. The optimal balance between availability of predictors, practical applicability and predictive measurement properties is not yet well understood [60, 61]. It is paramount that prediction models are validated thoroughly in order to make sure that the risk predictions are accurate across different populations and could be used with confidence for risk-stratified treatment [14, 24]. Finally, it would be ideal if the COPD community agreed on a single or very few different exacerbation prediction models since validations and implementation research are more efficient if there is a common prediction model compared with having many different prediction models [62]. Such a prediction model can always be improved by opportunely updating it (if necessary) in new cohorts [10, 63] and by adding promising predictors, but it needs to build upon prior knowledge on other datasets. Of course, separate models are justified if the decisions they inform are distinct, for example, in terms of time horizon.
Conclusions
Overall, none of the existing prediction models fulfilled the criteria for being ready for clinical application and use for risk-stratified treatment to personalise COPD care. The available COPD cohorts contain relevant populations, predictors and exacerbation measurements but a more harmonised approach to develop and validate high-quality predictions is needed to move personalised COPD medicine forward.
Supplementary material
Supplementary Material
Please note: supplementary material is not edited by the Editorial Office, and is uploaded as it has been supplied by the author.
Supplementary Data ERR-0061-2016_Supplementary_Data
Acknowledgements
We would like to thank Sarah Crook, Laura Barin, Laura Werlen and Alex Marzel (all University of Zurich, Zurich, Switzerland) for their comments.
Footnotes
This article has supplementary material available from err.ersjournals.com
Support statement: This study was supported by a grant from the University of Zurich (Zurich, Switzerland). Funding information for this article has been deposited with Open Funder Registry.
Conflict of interest: None declared.
Provenance: Submitted article, peer reviewed.
- Received May 23, 2016.
- Accepted July 25, 2016.
- Copyright ©ERS 2017.
ERR articles are open access and distributed under the terms of the Creative Commons Attribution Non-Commercial Licence 4.0.
References










